Hello everybody,
this is a new channel to broadcast frequent updates about SAI progress and training experiments.
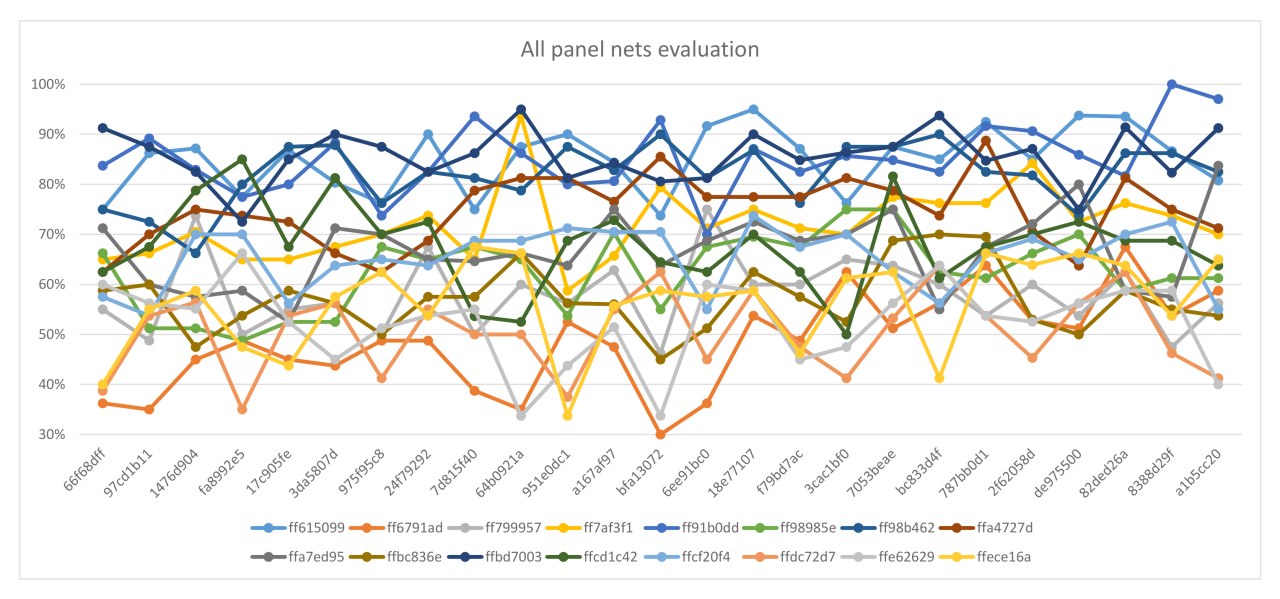
SAI progress



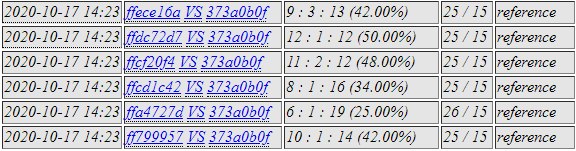
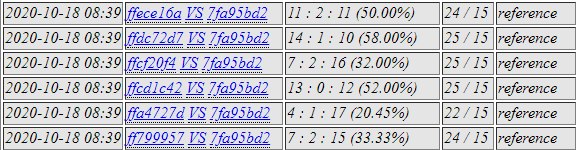
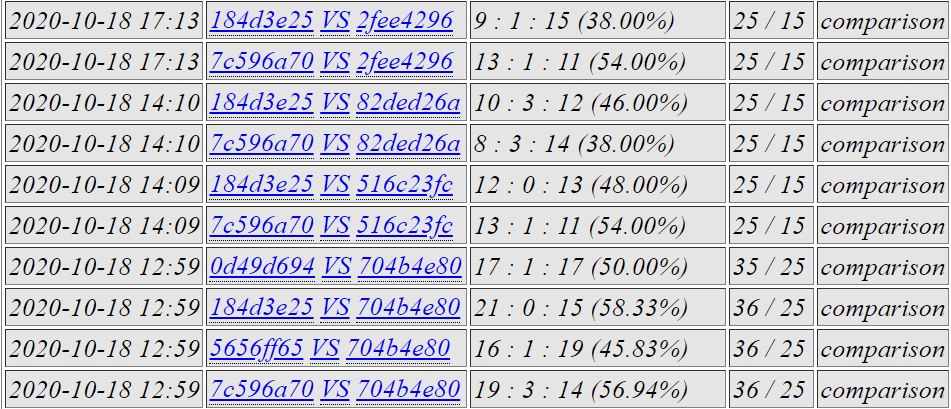
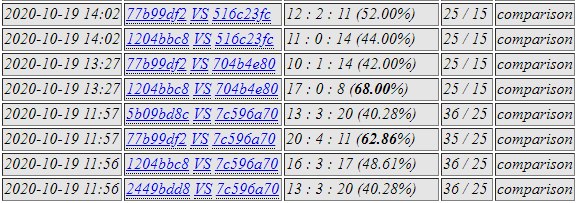
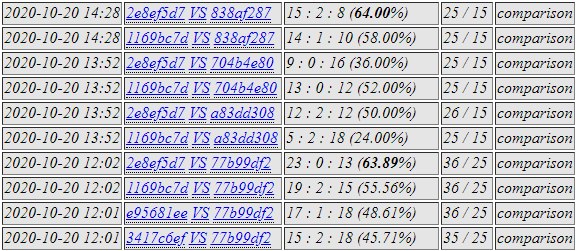
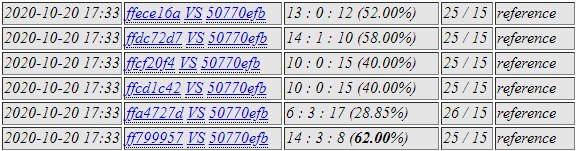
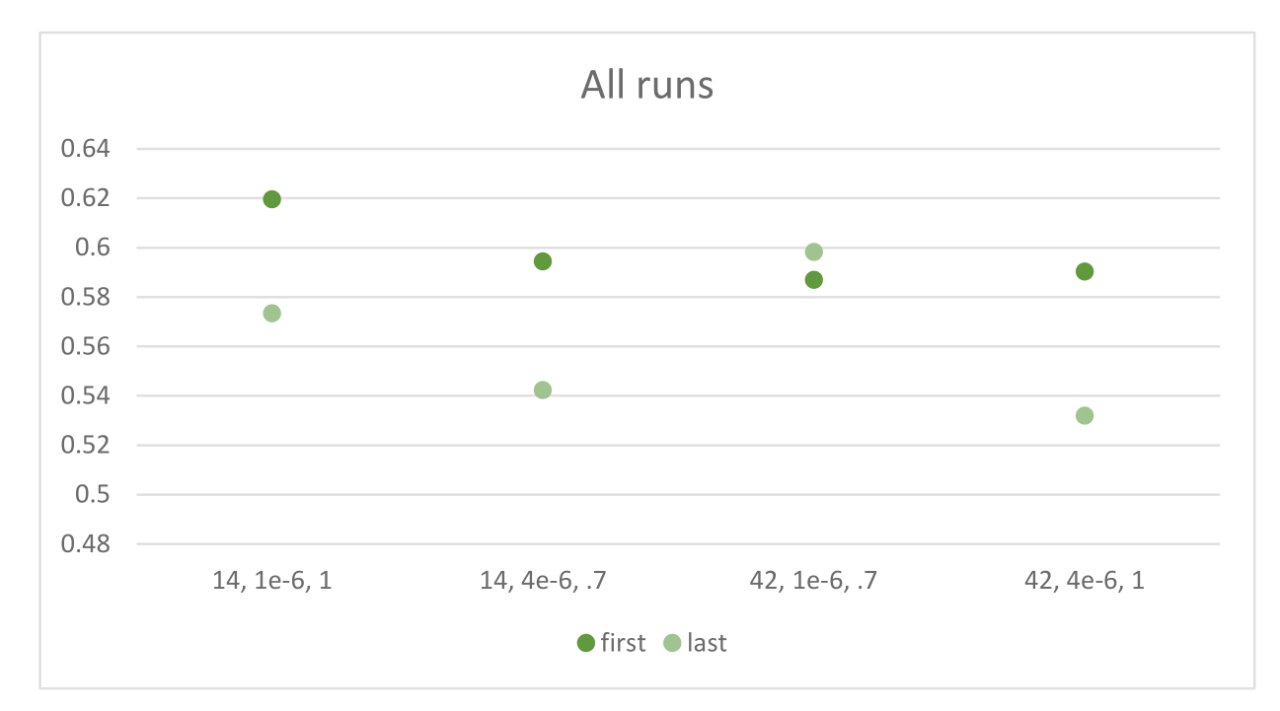
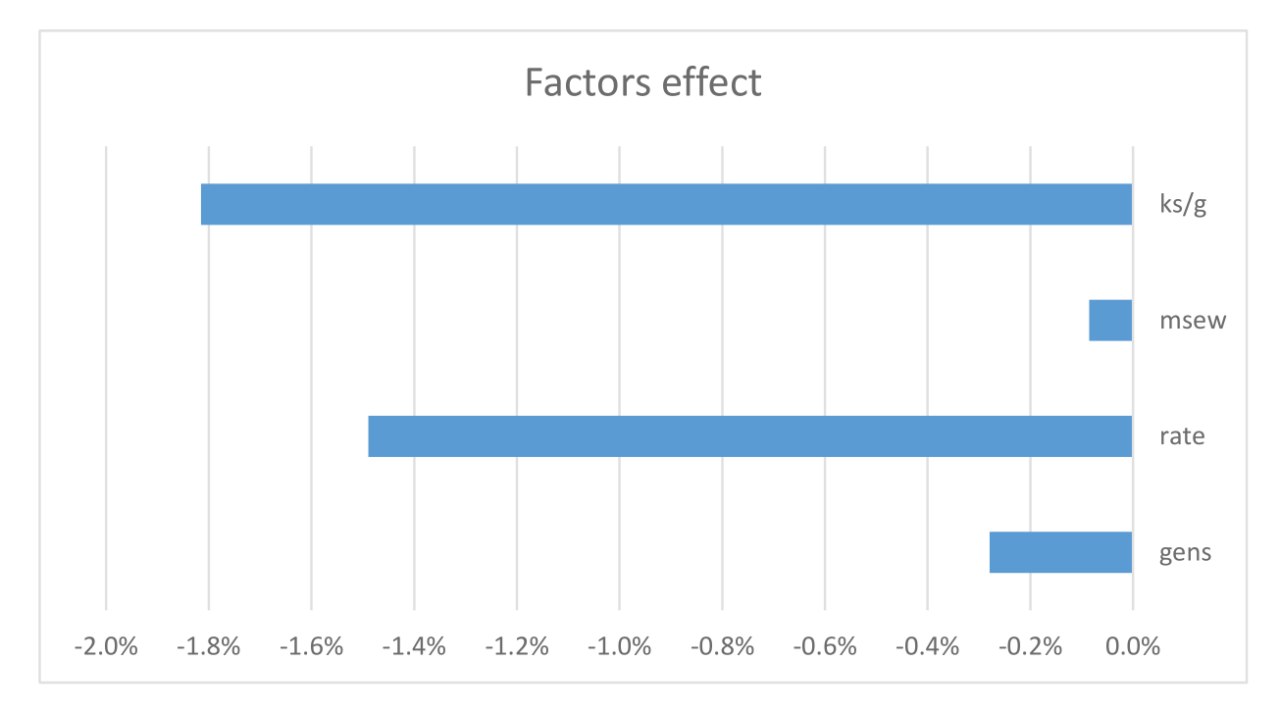
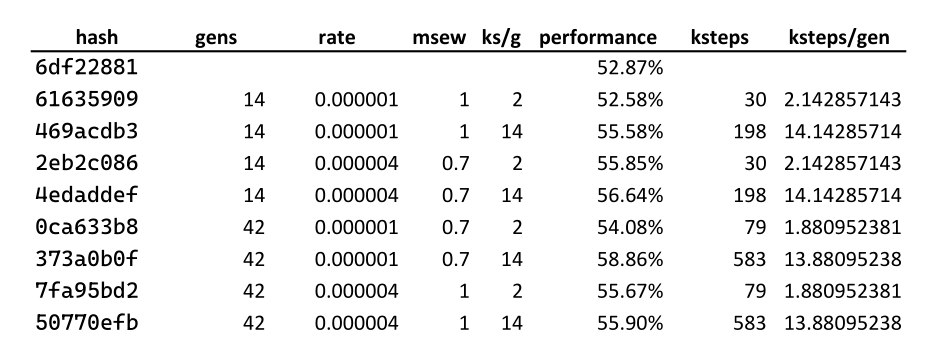
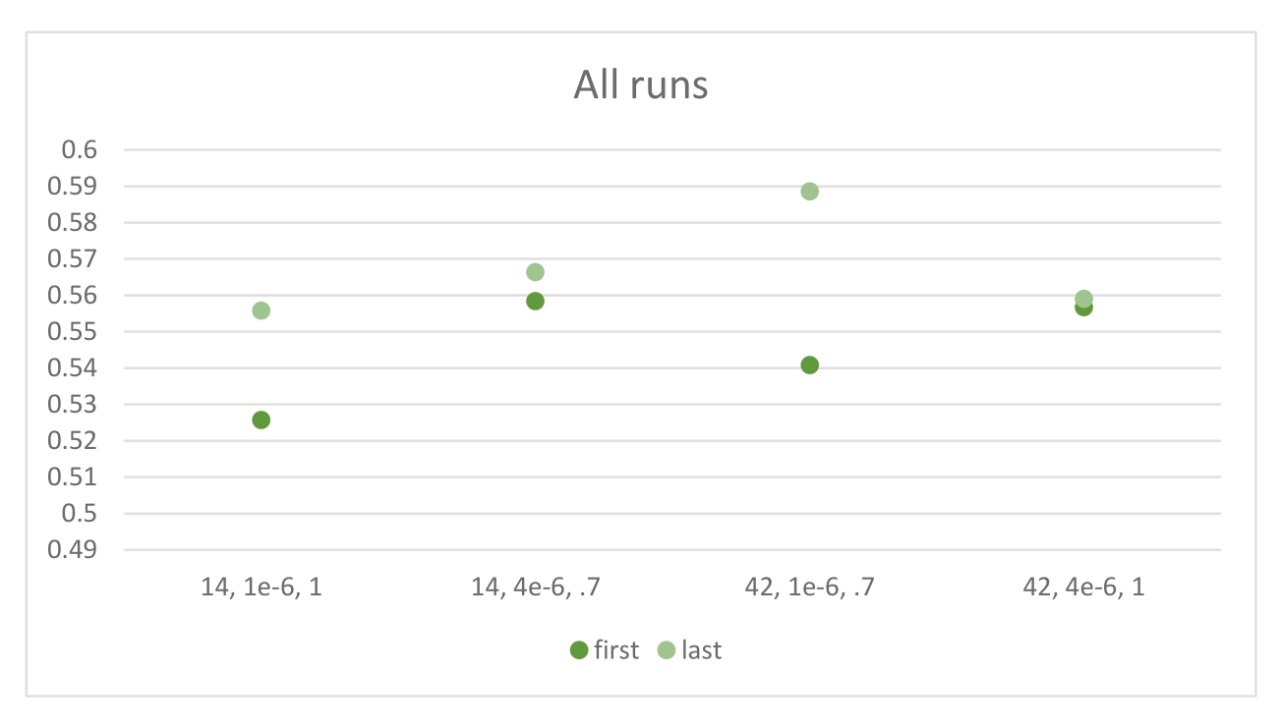
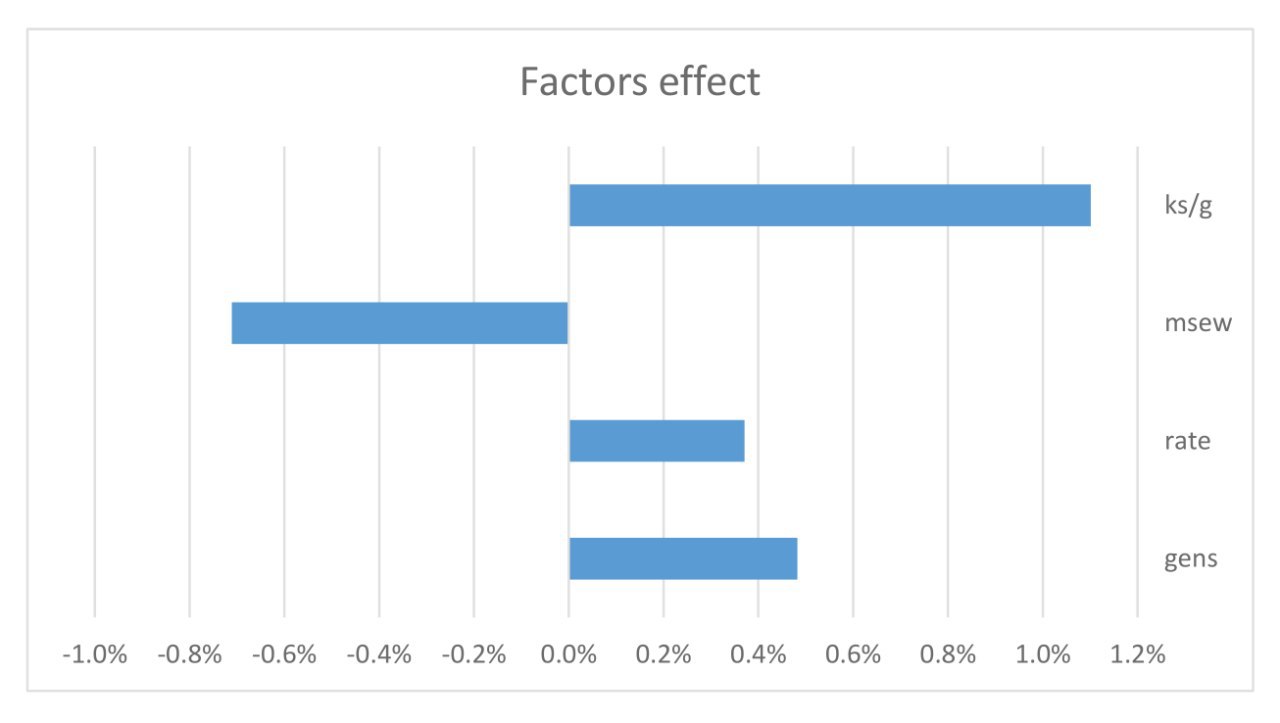
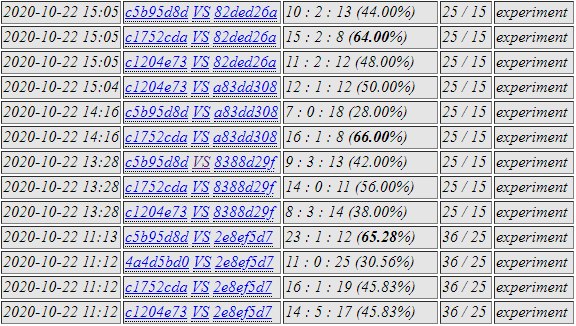
c175 and c5b9 against 2e8e and a83d
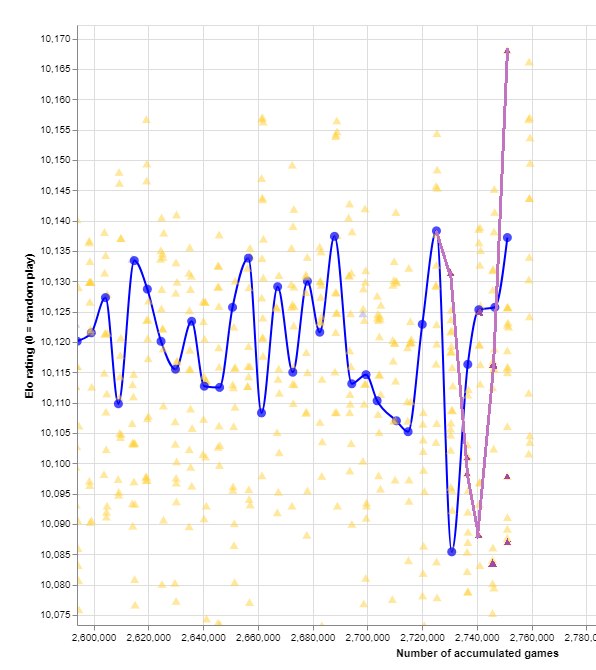
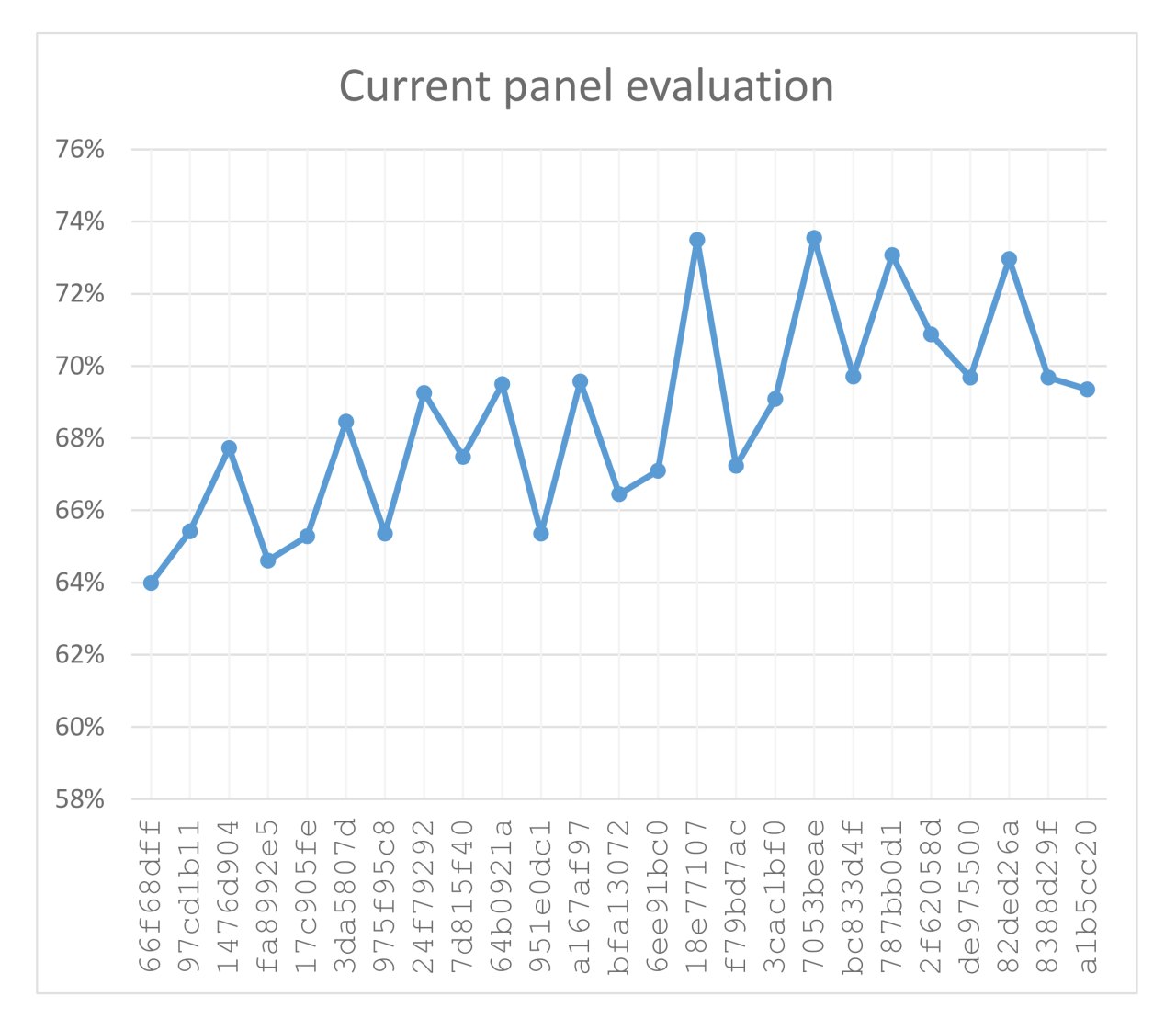
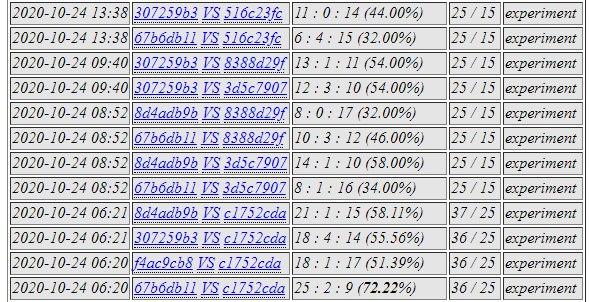
d16e was selected
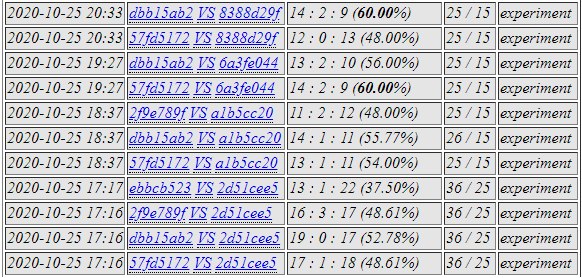
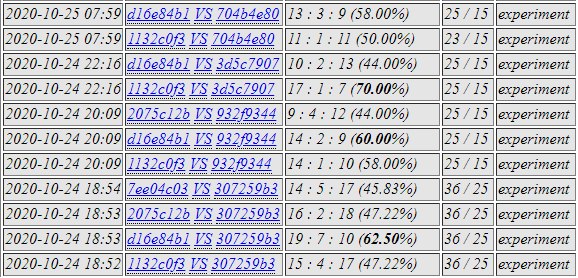
dbb1 was selected
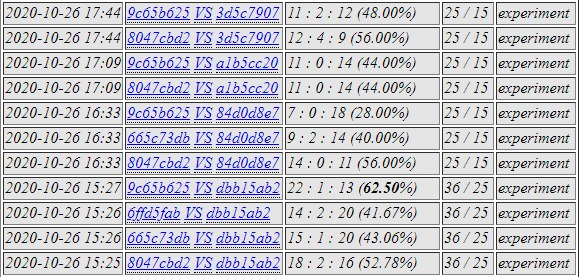
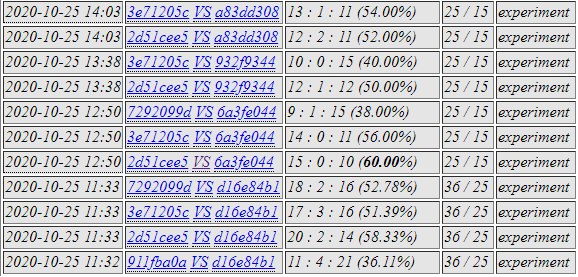
8047 was selected
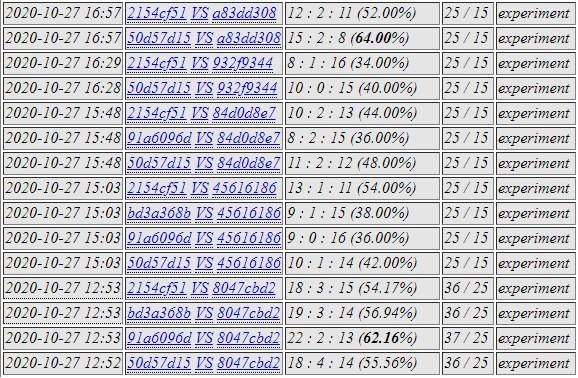
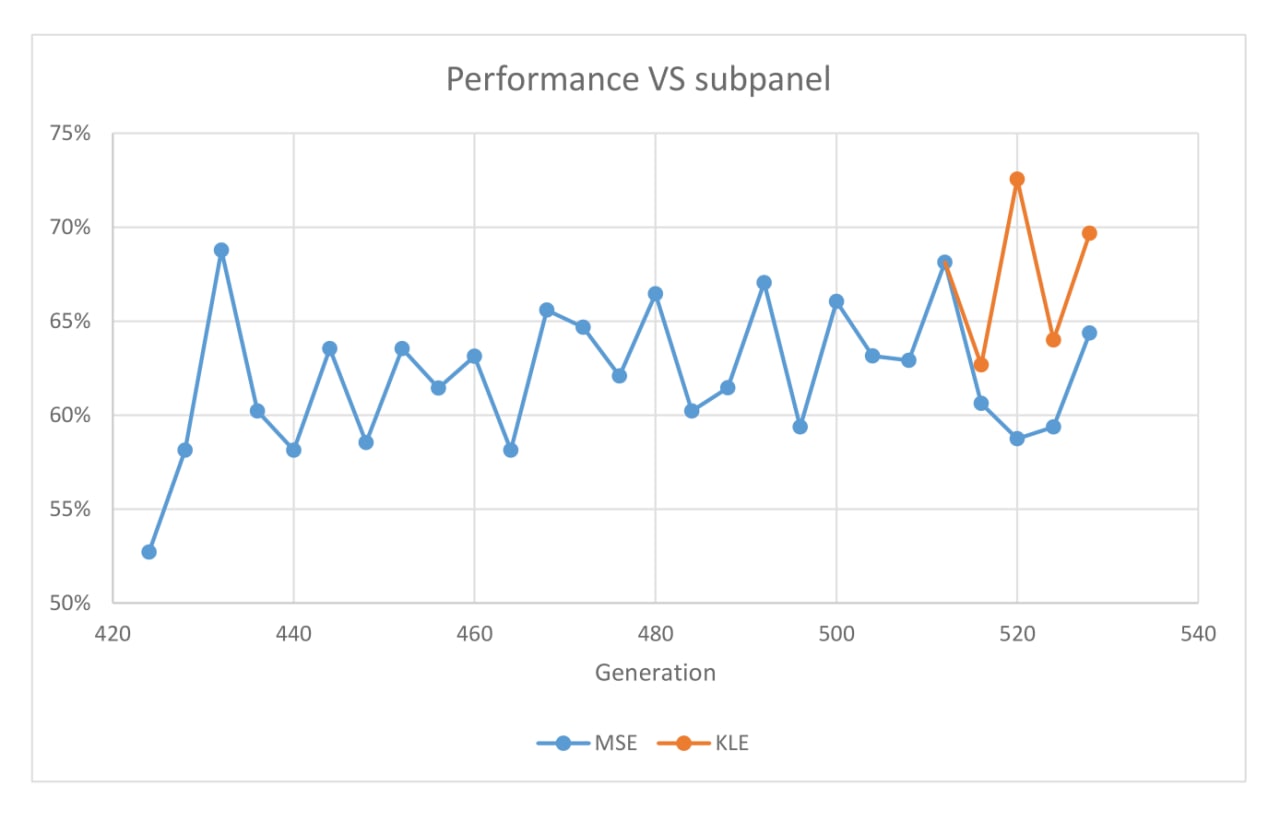
50d5 was selected. Subpanel matches in progress
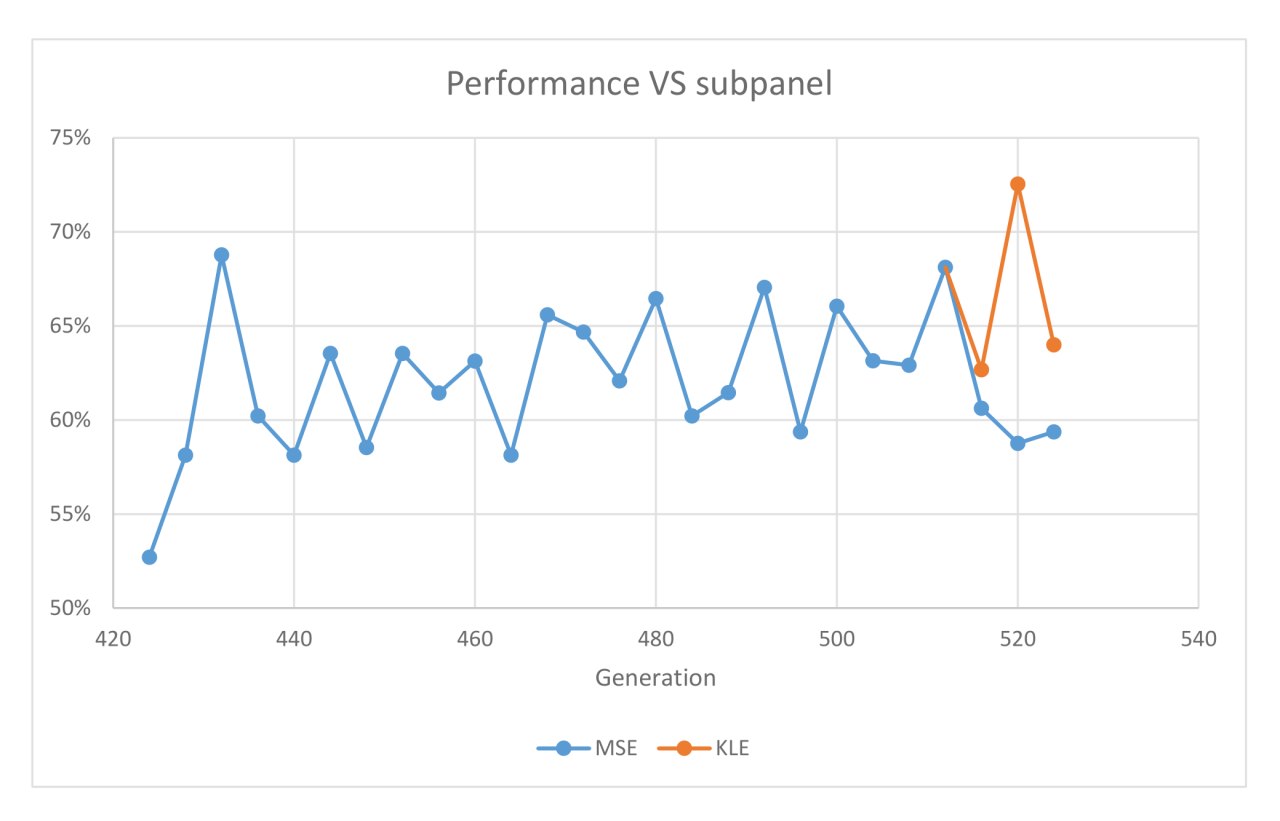

d1c6 selected. We will go light with matches in KLE experiment from now on.
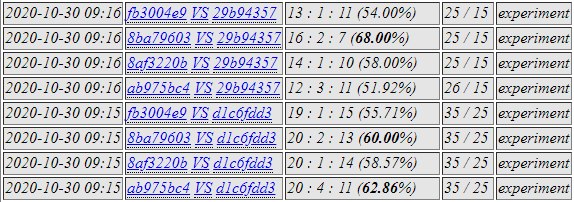
8ba7 selected.
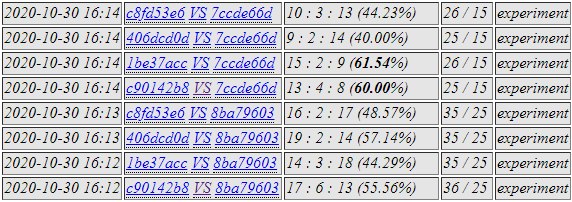
c901 selected.
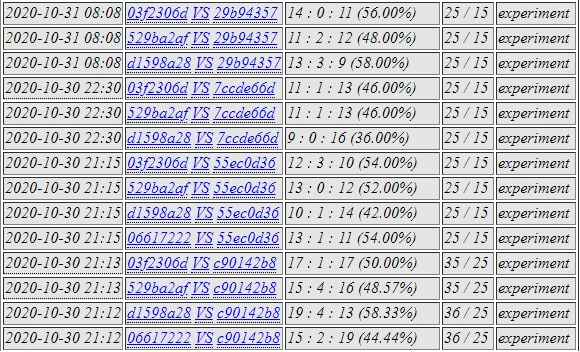
03f2 was selected
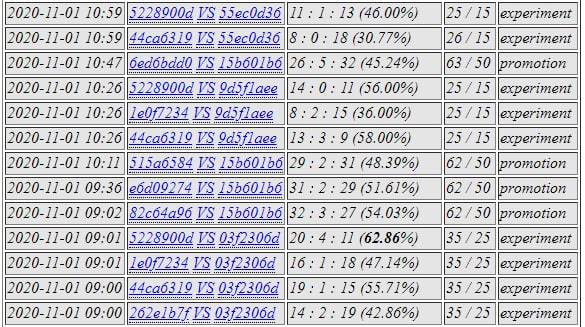
5228 was selected
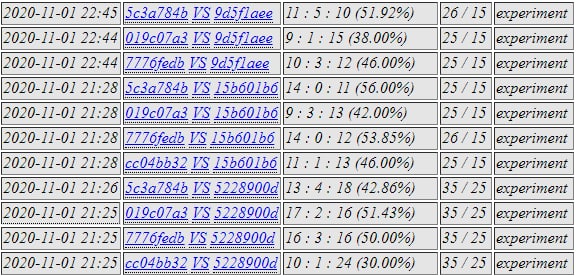
7776 was selected
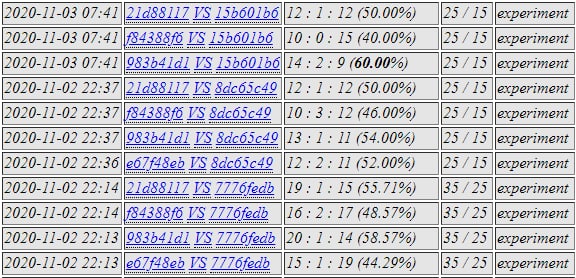
983b was selected
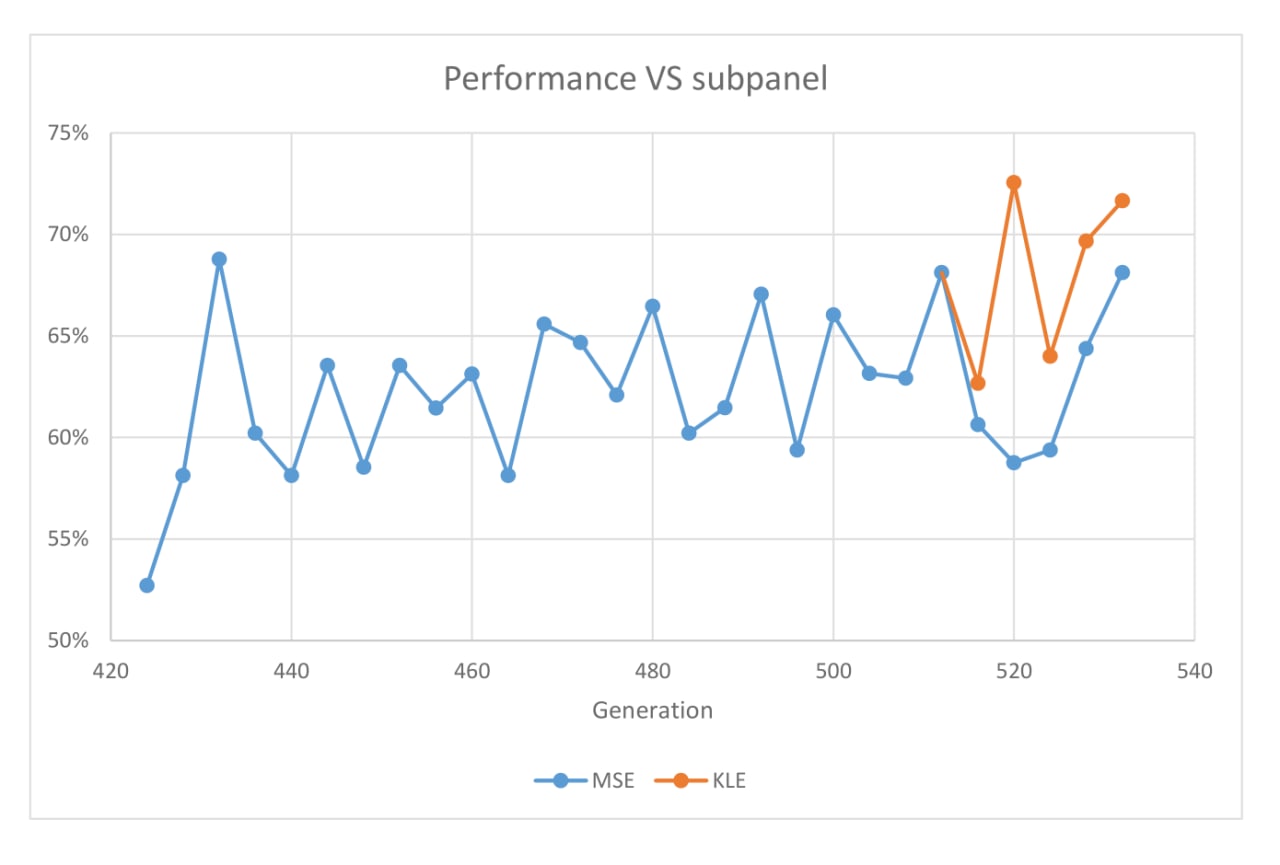
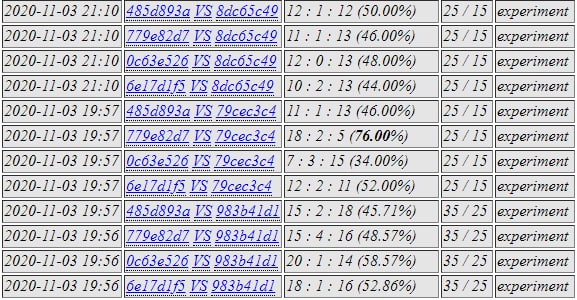
779e was selected.
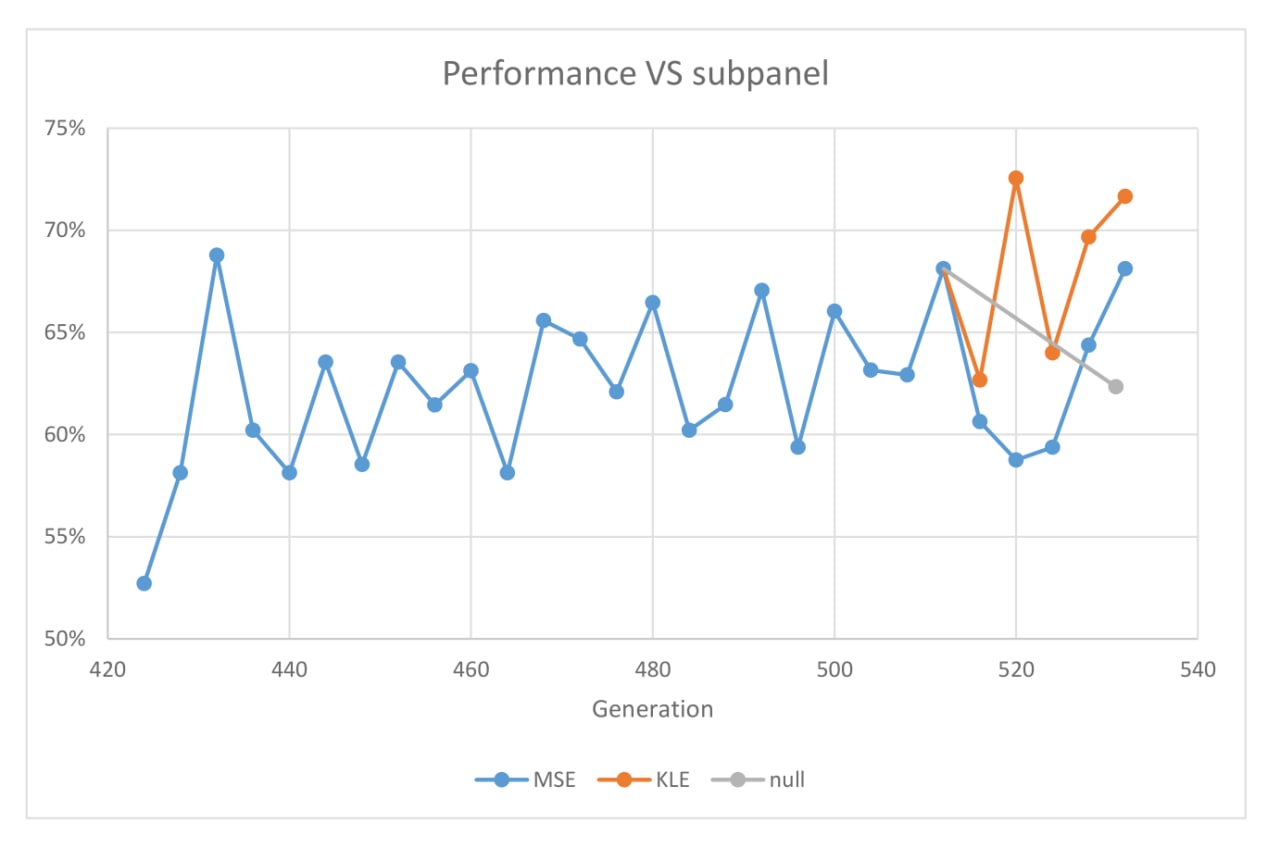
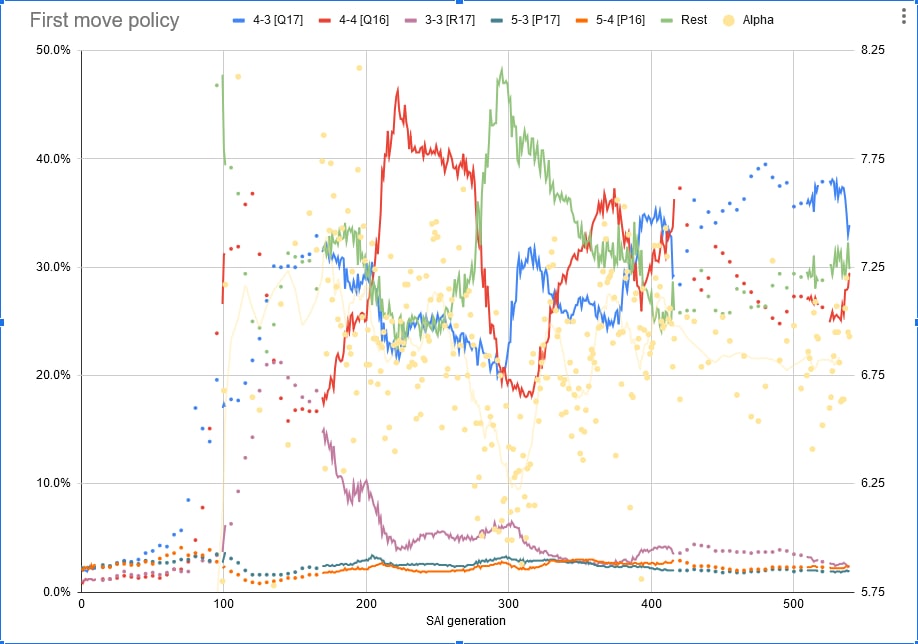
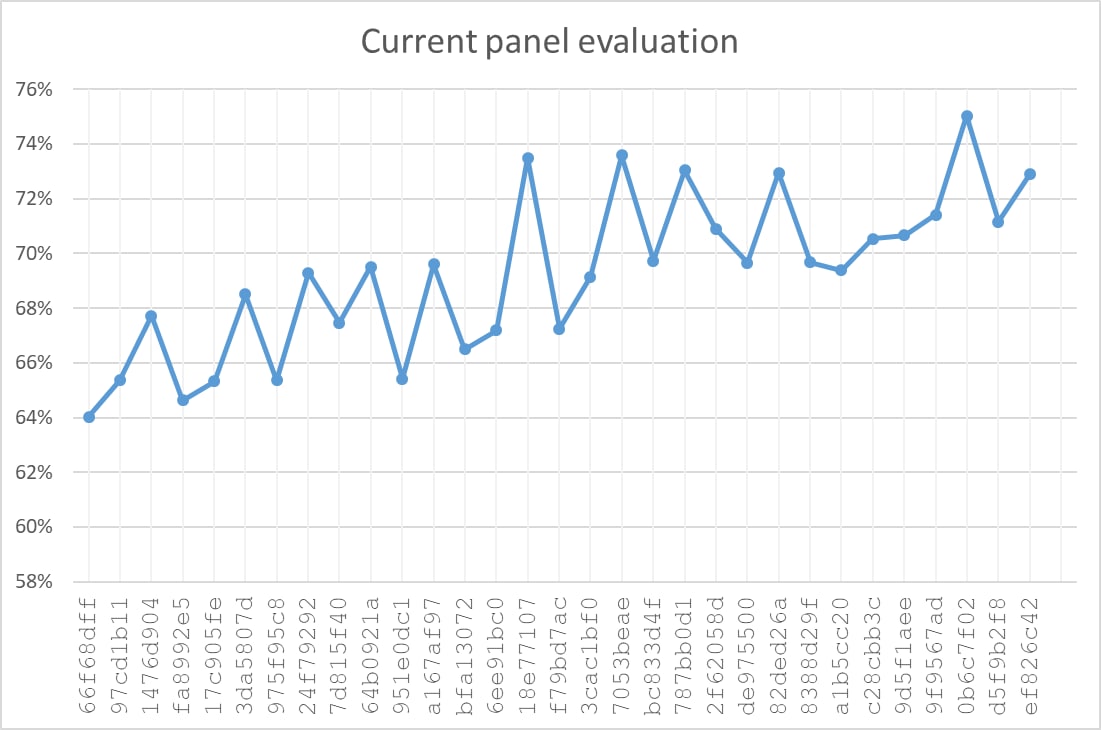
g1fd-792f and we decided to test it just to see how bad it was.
6fd3aa against the subpanel now
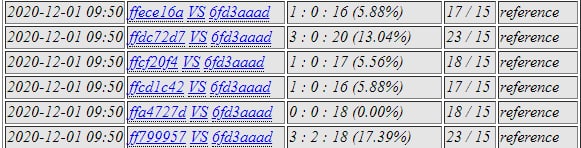
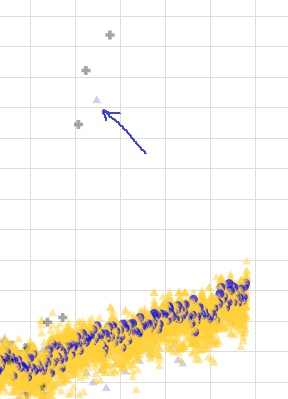
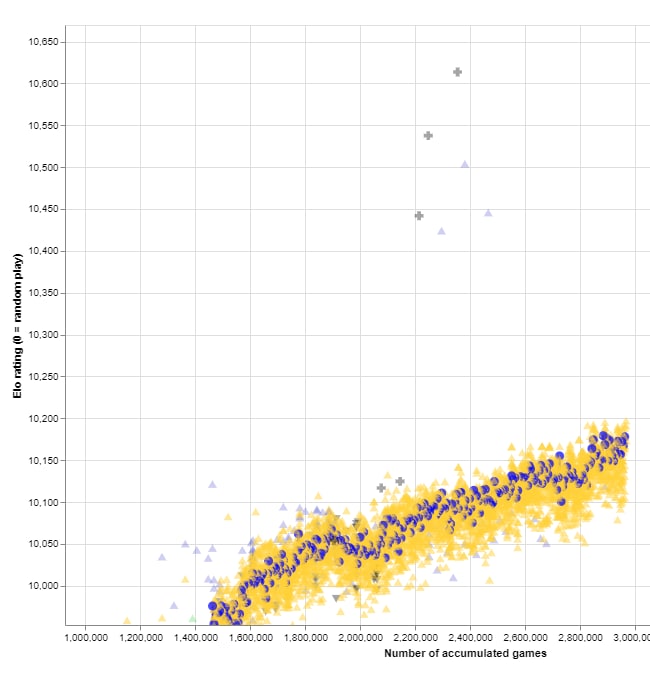
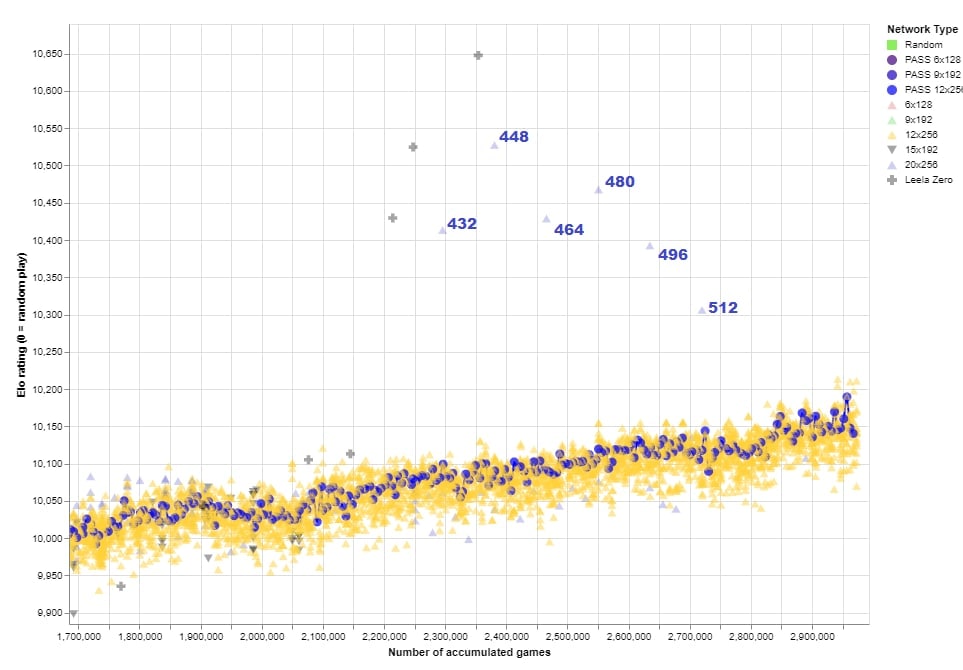

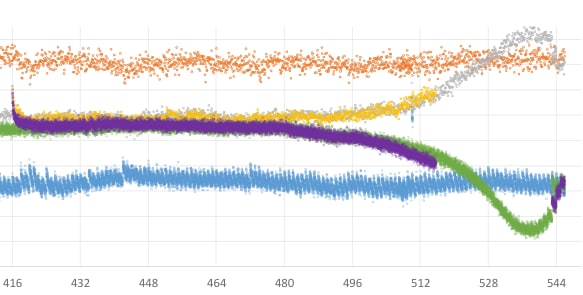
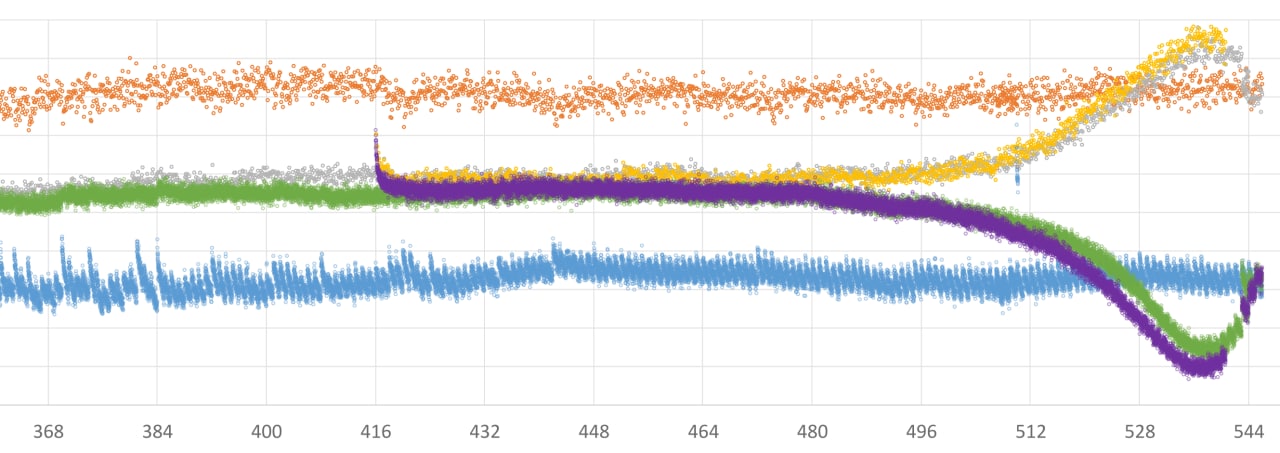
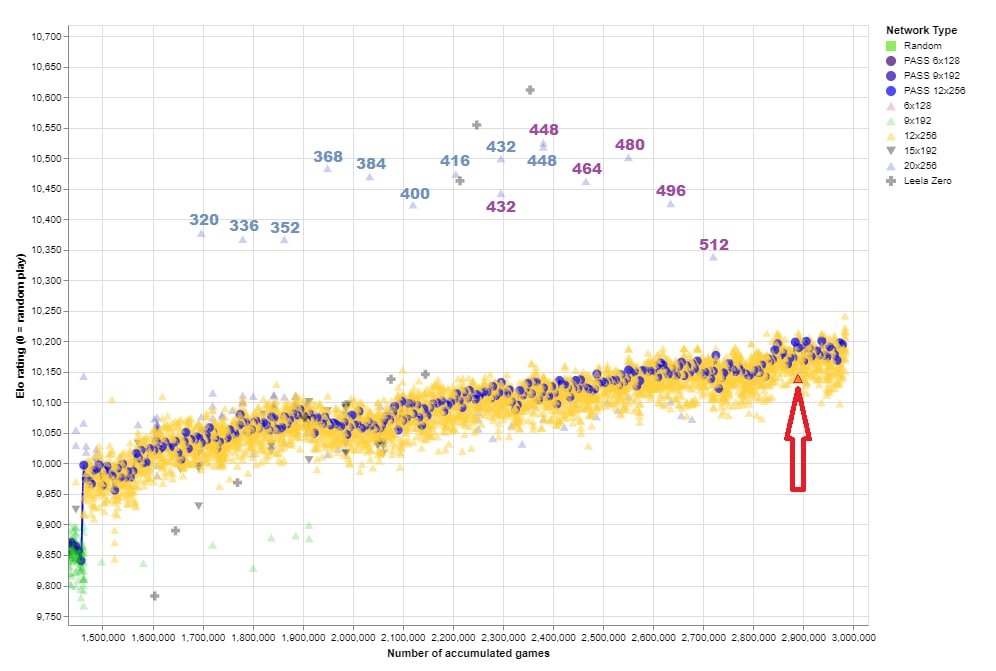
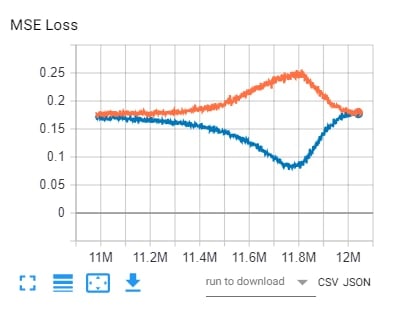
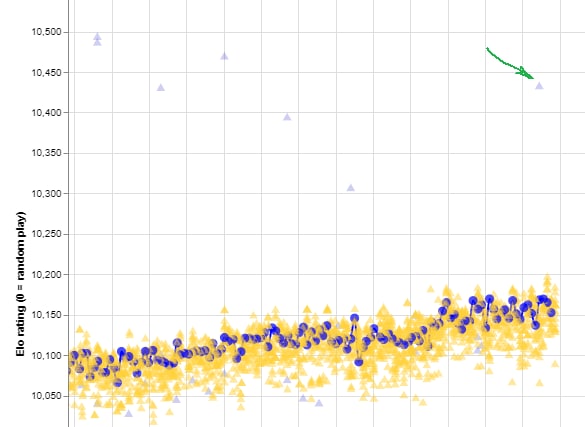
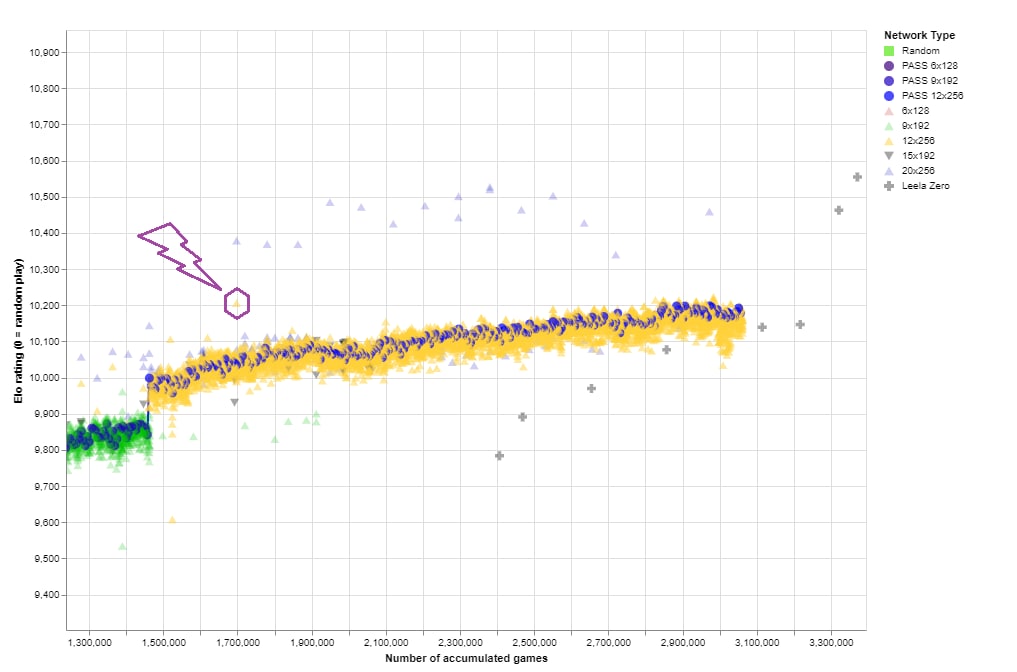
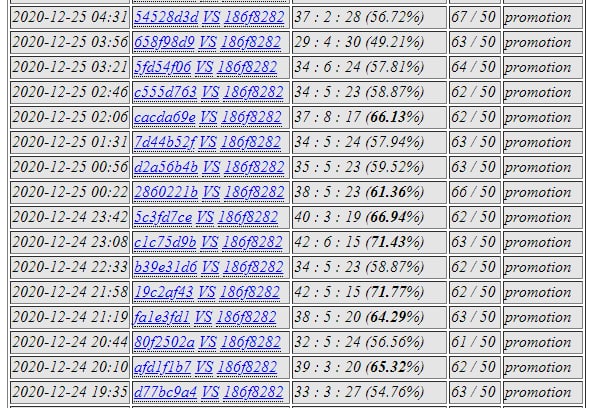
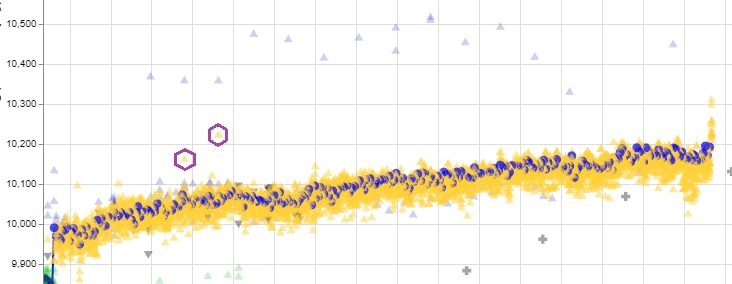
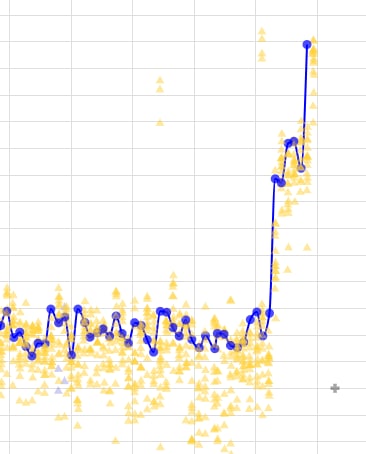
186f82 network was shocking!

{kind=link}
{kind=link}
{kind=link}